
Historique de la page
| Sv translation | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||
L'explorateur de donnéesL'onglet DataExplorer vous permet, comme son nom l'indique en anglais, de parcourir les données de la base, en d'autres termes l'historique des métriques collectées.
La partie haute de la fenêtre permet d'écrire ou générer la requête :
L'affichage au bas de la fenêtre vous présente le graphe correspondant à la requête. Il est soumis aux règles de rafraichissement et de période telles que définies en haut de la page, de même que sur les tableaux de bord :
Pour rechercher et analyser une métrique :
Fonctions utiles/affinage de la requêteModifier la durée affichéeCette partie de la requête définit la durée à afficher :
Elle signifie de façon littérale : les données dont le temps est supérieur à aujourd'hui moins 7 jours (7d = 7 days), soit les données des 7 derniers jours
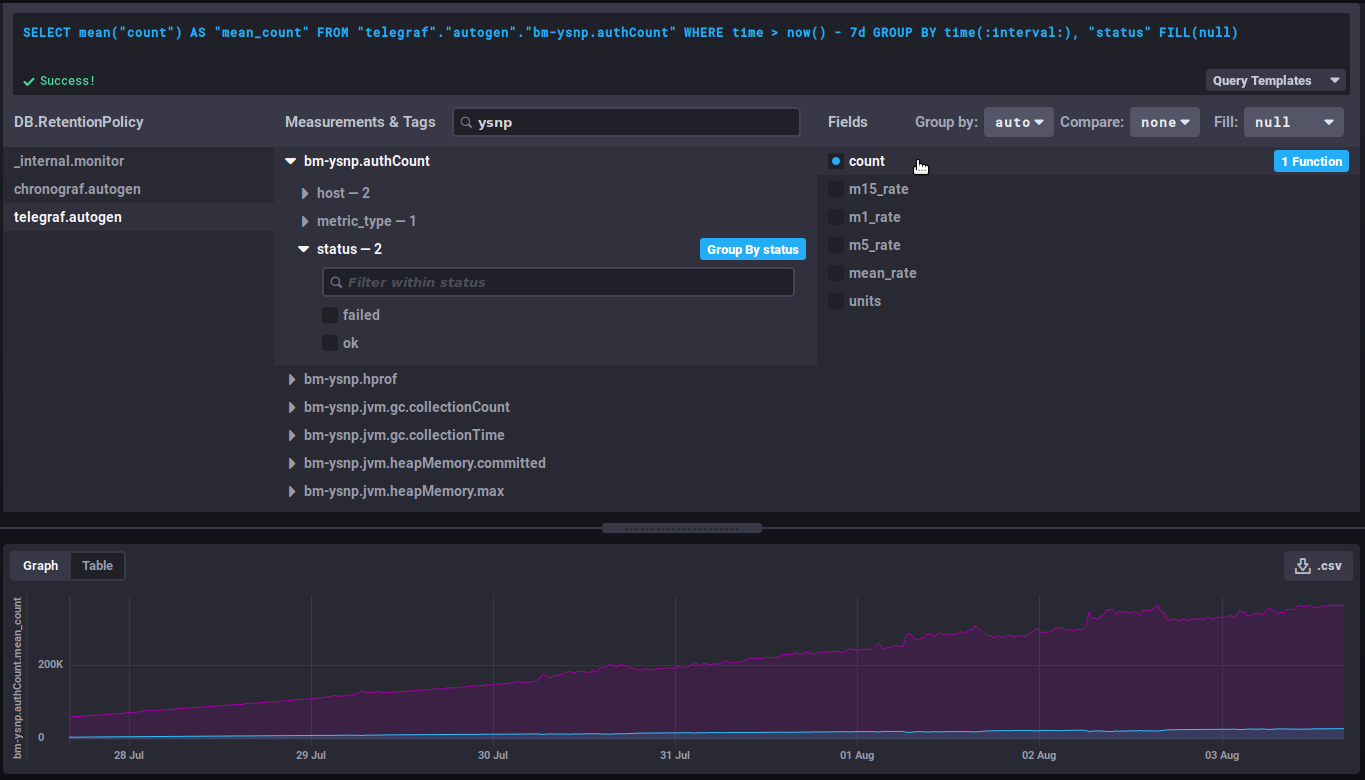
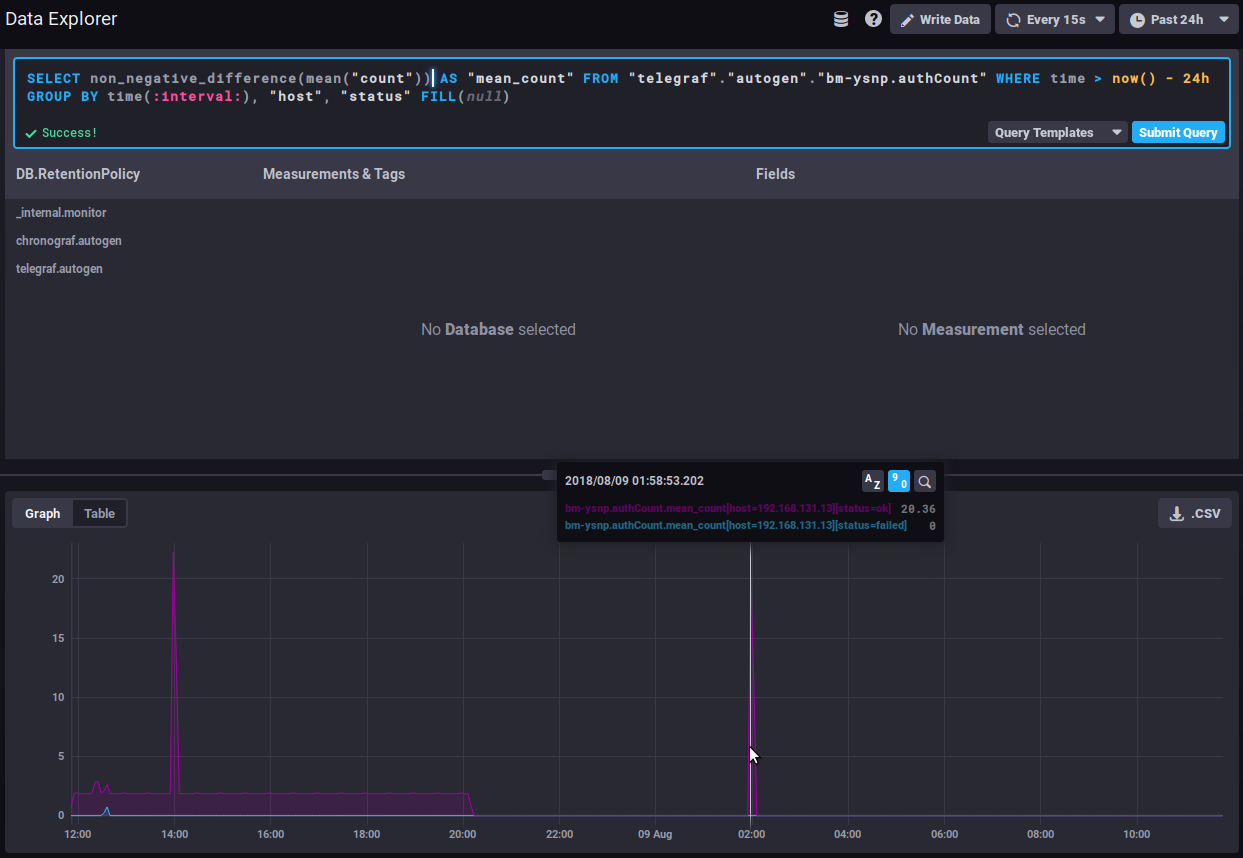
Évolution d'un compteurLes données de type counter sont cumulatives et augmentent donc régulièrement. Dans ce cas c'est leur évolution qui est plus intéressante que la valeur elle-même. Par exemple la donnée non_negative_differencePour observer cette évolution on pourra utiliser la fonction "non_negative_difference" qui donne la différence non négative entre 2 points du graphique. En reprenant l'exemple du nombre d'authentifications, le graphique suivant sans fonction appliquée, montre le nombre moyen d'authentifications traitées par le composant ysnp sur les dernières 24h, par serveur et par statut :
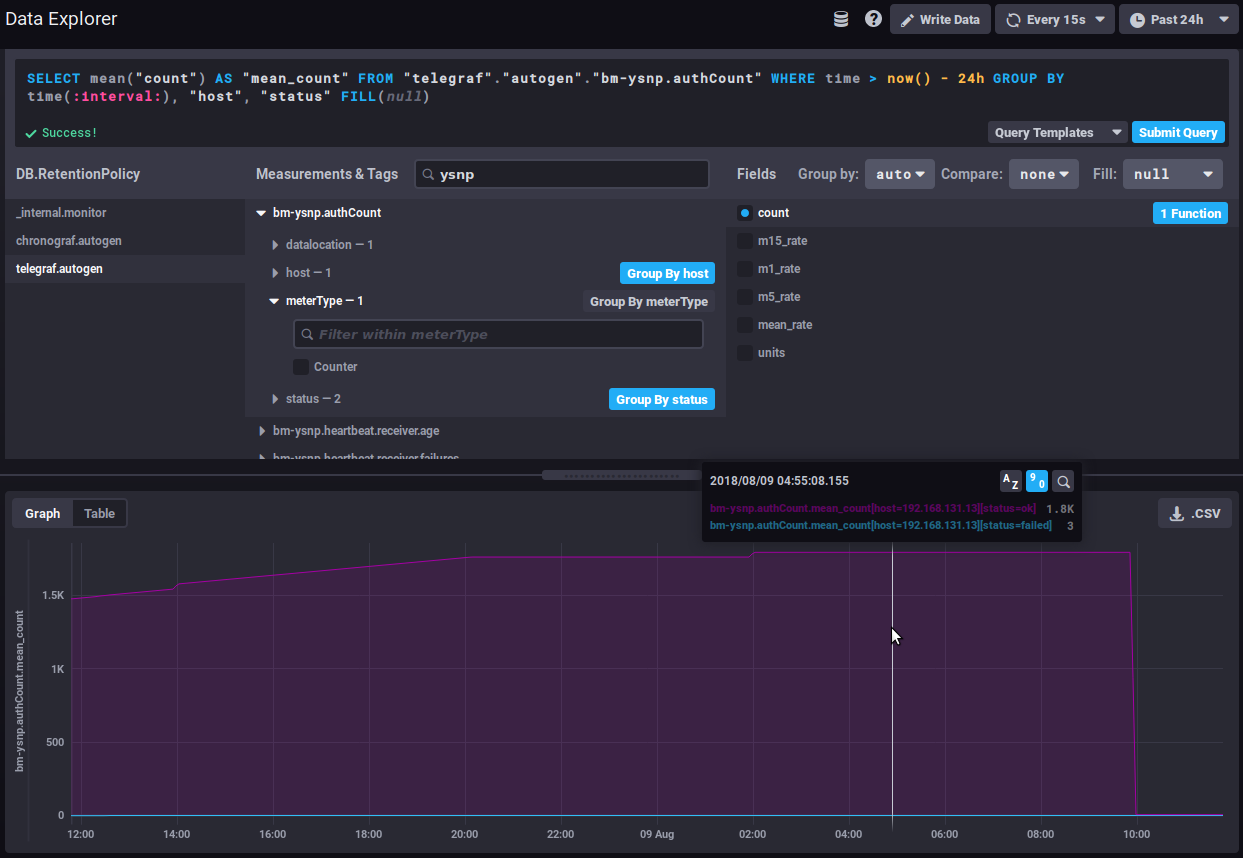
En utilisant la fonction de différence par intervalles, le graphique donne alors le nombre d'authentification pour chaque intervalle de temps, on voit donc à présent de quelle façon la quantité d'authentifications traitées évolue :
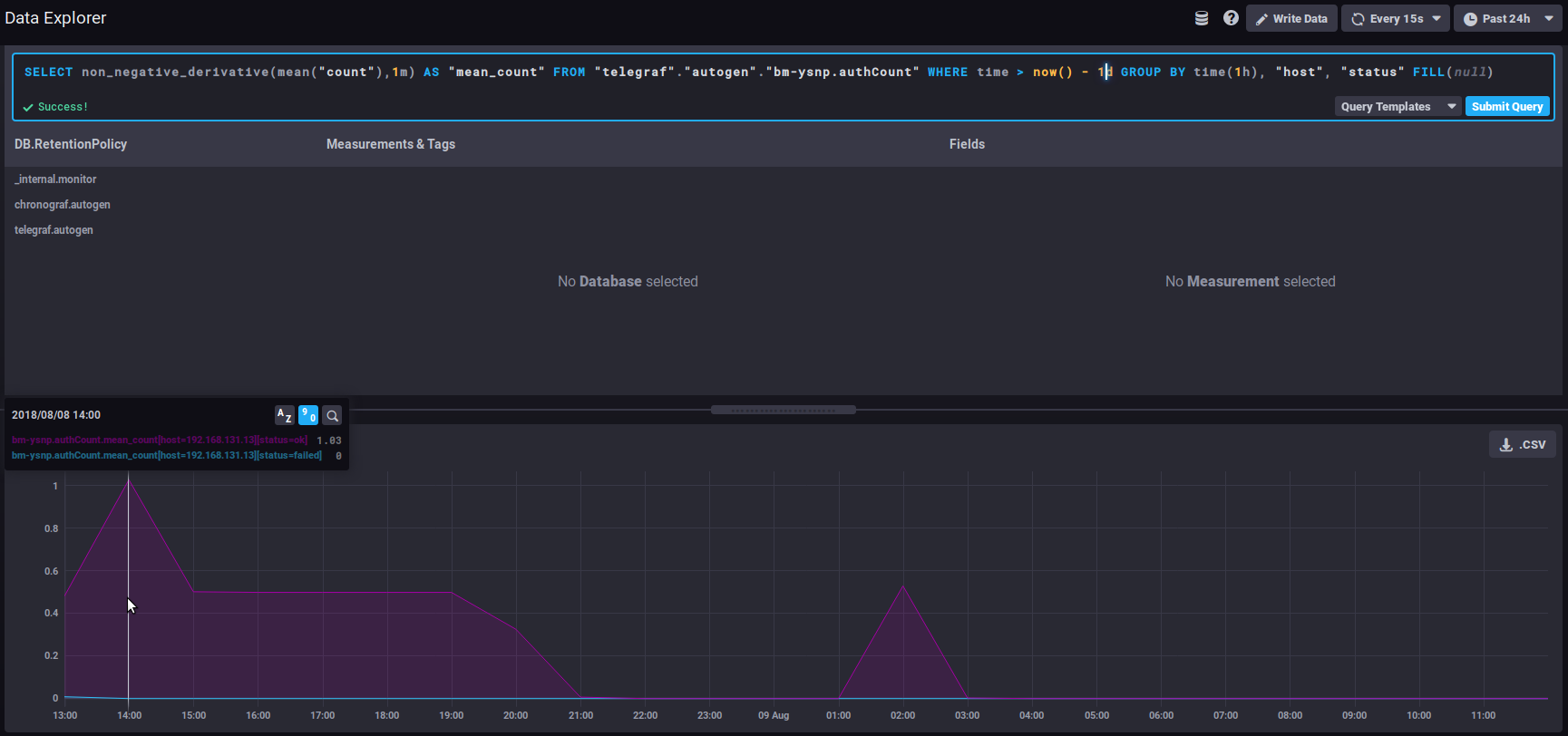
non_negative_derivativeUne autre fonction permet d'obtenir la courbe d'évolution d'une donnée mais en apportant un paramétrage supplémentaire : non_negative_derivative. Cette fonction propose elle aussi le calcul de la différence entre 2 points, mais elle permet en plus de préciser l'unité. Ainsi, la requête ci-dessous présente le nombre moyen de connexions (mean("count")) par minute (non_negative_derivative(...,1m)) lors des dernières 24h (where time > now() - 1d) pour chaque heure (group by time(1h)) :
Les métriques de type distsum comportent 2 informations :
Ainsi, on a par exemple les couples suivants :
Prenons par exemple la métrique Ces données permettent d'établir des moyennes de taille par message et ainsi voir si la taille moyenne des messages évolue de façon brutale et anormale. Liens utilesPour aller plus loin dans le langage de requêtes InfluxQL, se reporter à la documentation dédiée : https://docs.influxdata.com/influxdb/v1.6/query_language/ Voir en particulier les fonctions : https://docs.influxdata.com/influxdb/v1.6/query_language/functions/ Et les regroupements par temps : https://docs.influxdata.com/influxdb/v1.6/query_language/data_exploration/#advanced-group-by-time-syntax Aller plus loin avec les graphiquesL'outil graphique du DataExplorer propose des options limitées, il est par exemple impossible de créer un graphe empilé afin de voir les sommes de 2 courbes. Pour faire cela, il faut passer par les courbes des tableaux de bord (voir plus bas) : Les tableaux de bordL'onglet Dashboards vous permet d'accéder aux tableaux de bord. Il s'agit de pages vous permettant de regrouper les données de votre choix. Par défaut 3 tableaux de bords sont pré-configurés et donnés pour exemples :
Vous pouvez rajouter autant de tableaux que vous le souhaitez afin d'avoir des vues personnalisées sur les données qui vous intéressent, en regroupant les données par type, par pertinence, par module, etc.
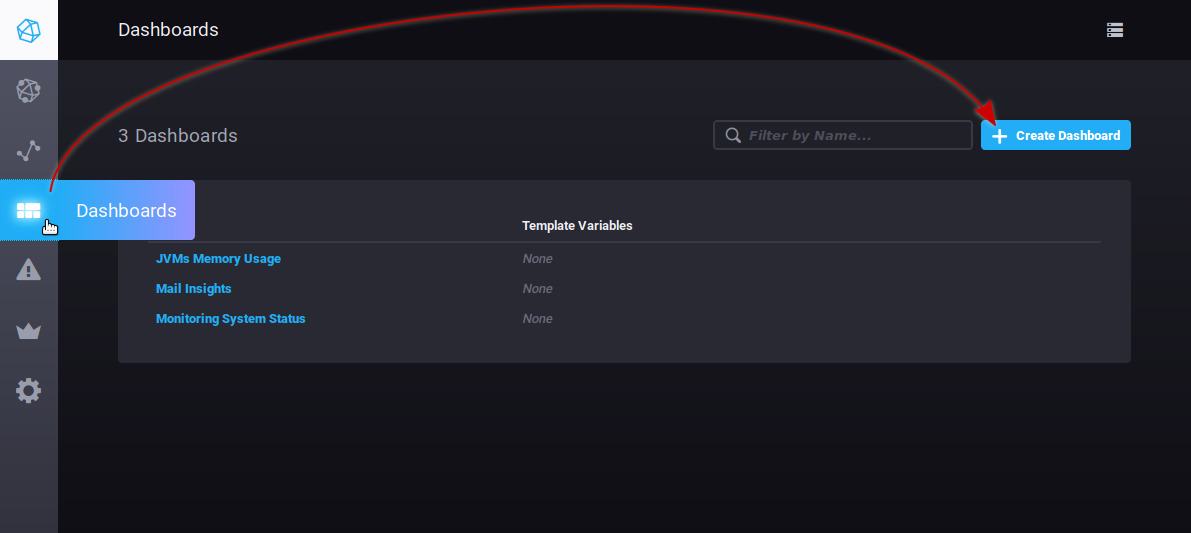
Pour créer un nouveau tableau de bord, rendez-vous à l'accueil de l'onglet Dashboard et cliquez sur le bouton "Create dashboard" :
Le tableau est aussitôt créé, une nouvelle vue vide est présentée :
Cliquez sur "Name this dashboard" pour que le champ devienne éditable, saisissez alors un nom pour votre tableau :
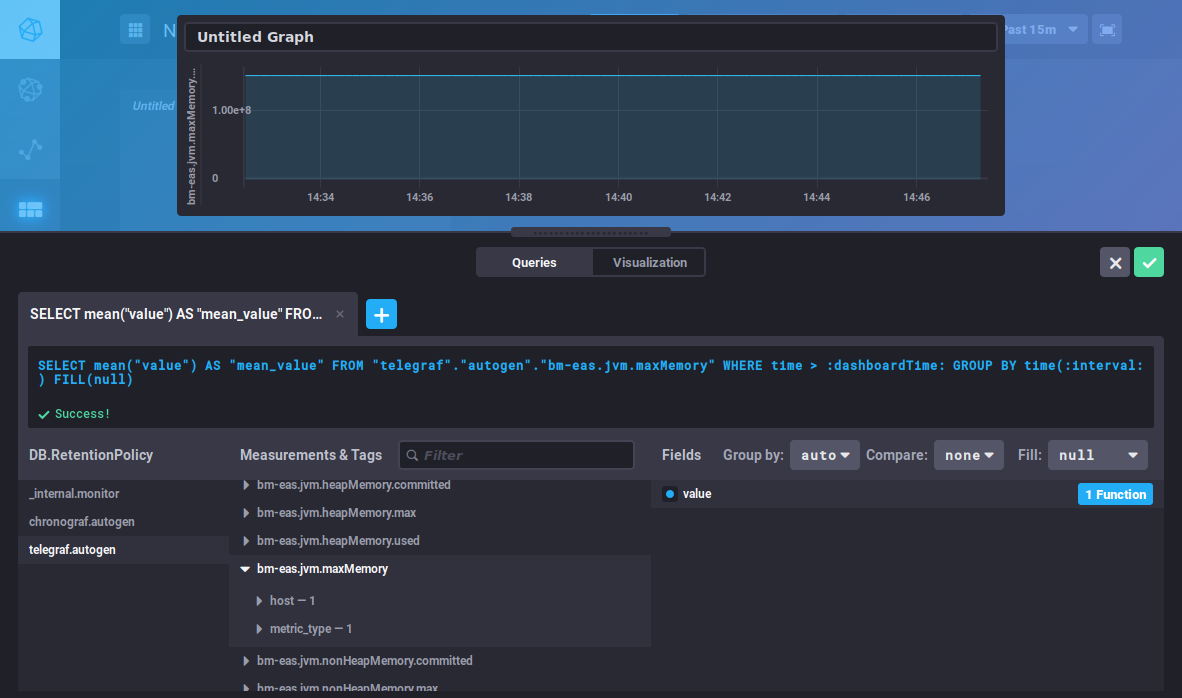
Pour ajouter un graphique dans la zone déjà présente, cliquez sur L'éditeur de requête apparaît, vous permettant de créer votre requête soit par saisie directe soit grâce au navigateur de base de données, et vous propose une vue en temps réel du graphique correspondant :
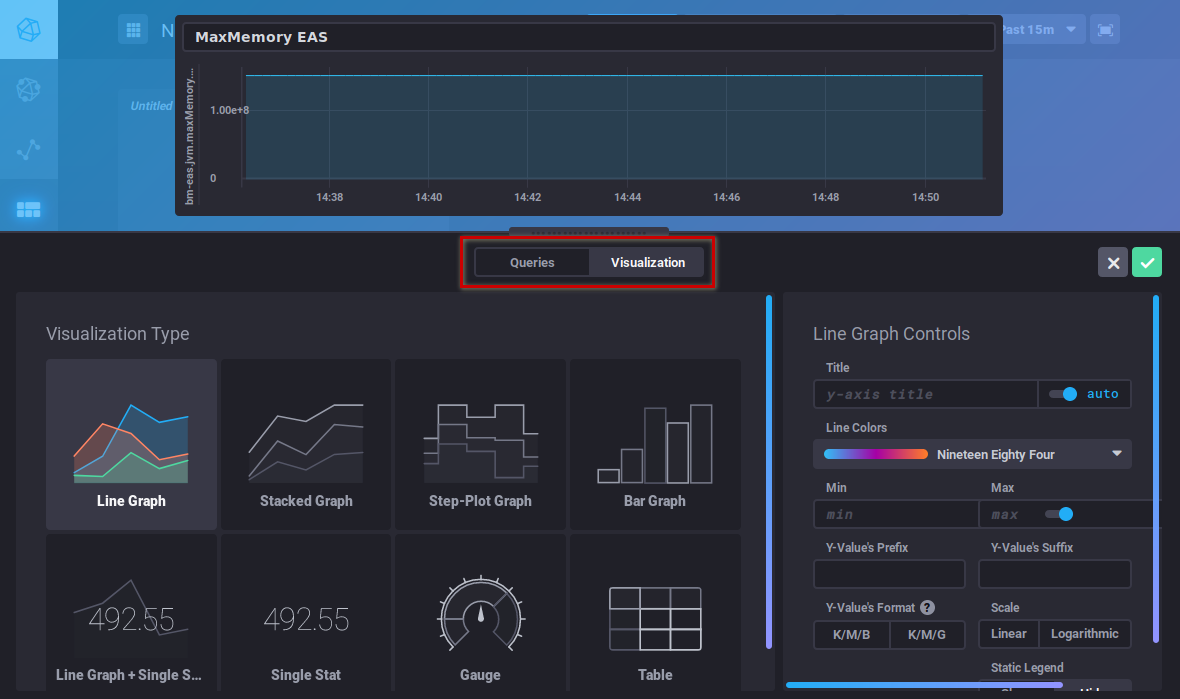
Cet éditeur est similaire à celui du DataExplorer, vous pouvez vous référez à la section précédente pour la recherche de métriques et la construction des requêtes. Le bouton " Visualization " vous permet de choisir le type de graphique souhaité et de personnaliser celui-ci :
Une fois votre graphique créé, cliquez sur "Save" en haut à droite de l'éditeur pour le sauvegarder et l'ajouter à la zone :
Cliquez sur
En haut à droite de chaque cellule, des boutons vous permettent :
Cliquer sur l'icône souhaitée pour faire apparaître le menu des actions possibles.
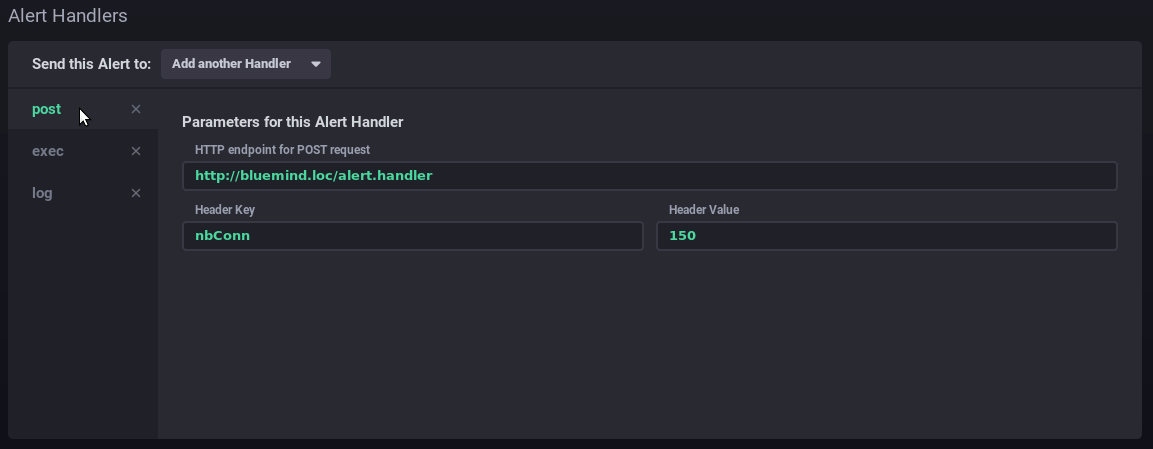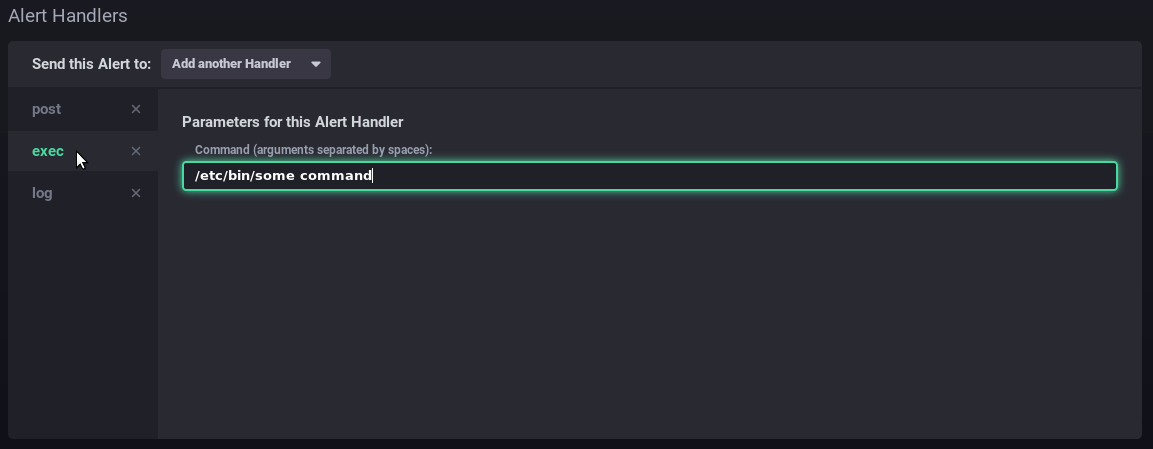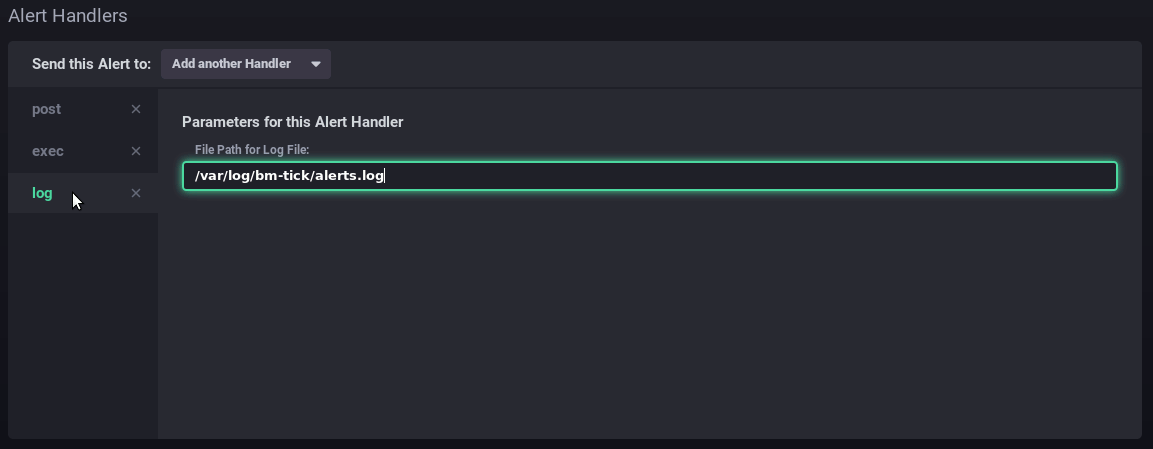
Les alertesL'onglet Alerting permet d'accéder à la gestion des alertes ainsi qu'à l'historique des alertes levées.
Les alertes peuvent se présenter sous forme de scripts ou de règles d'alertes. Par défaut aucune règle d'alerte n'est présente à l'installation, en revanche un certain nombre de scripts sont pré-configurés, vous pouvez les modifier et/ou en rajouter autant que vous le souhaitez.
Les alertes
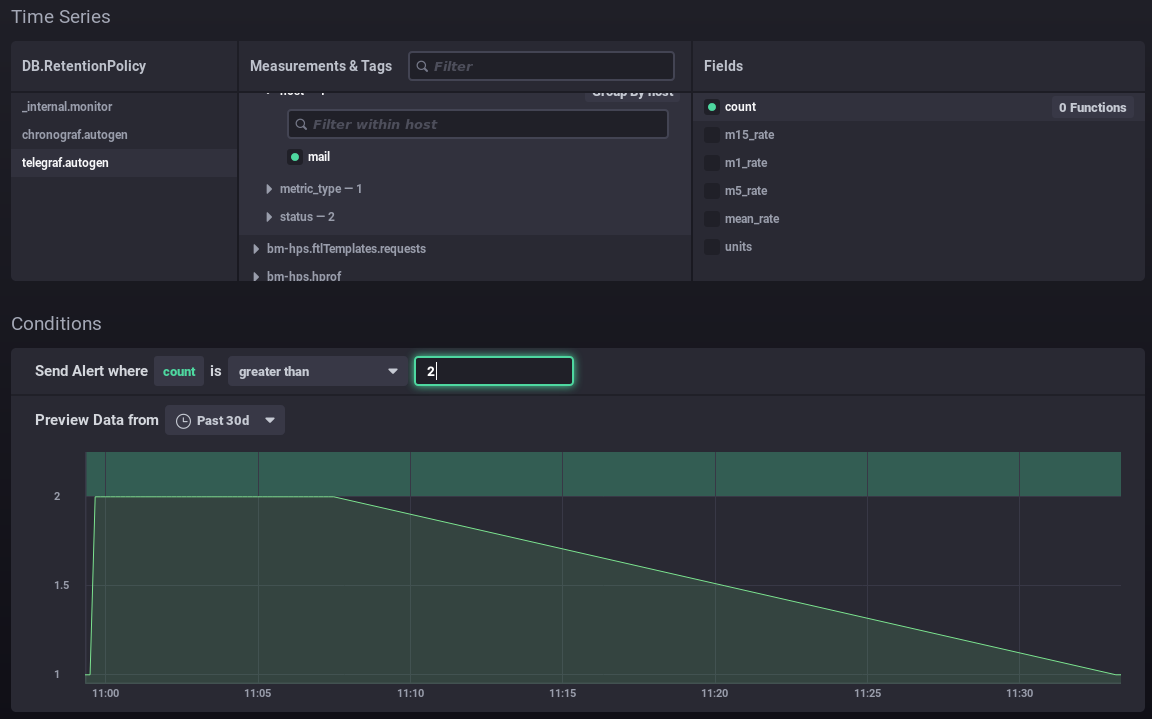
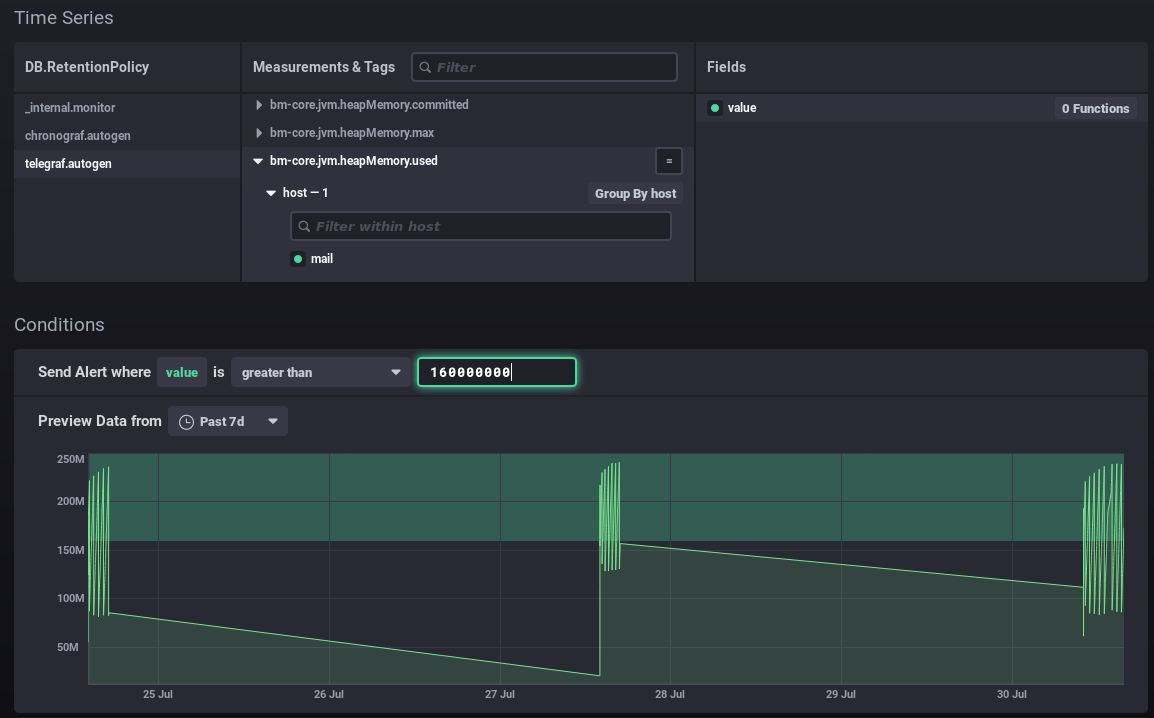
Remplissez (ou corriger) ensuite les différentes parties du formulaire :
Les scriptsLes scripts permettent une gestion plus fine et experte des alertes. Chaque alerte créée sous forme de règle est aussi présente sous forme de script et peut être éditée de cette façon.
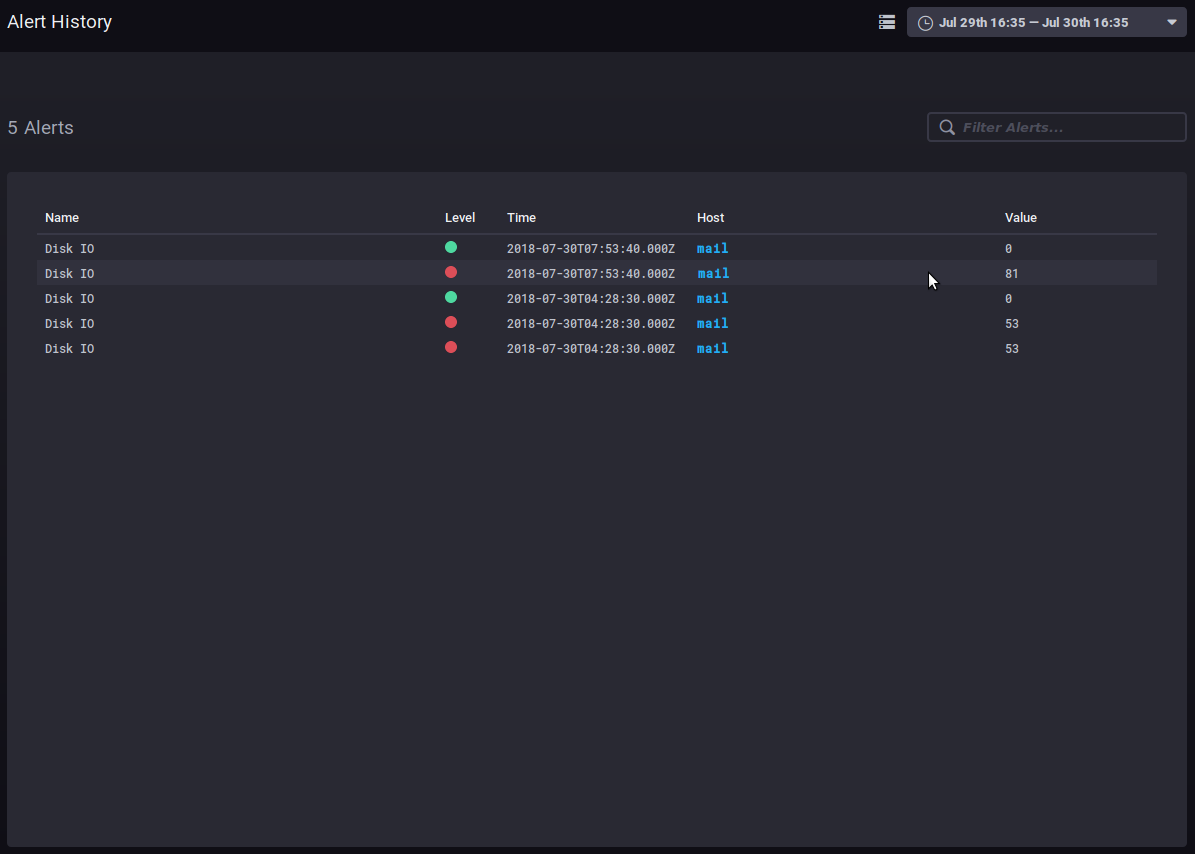
Pour plus d'information sur l'écriture de scripts, vous pouvez vous référer à la documentation produit : https://docs.influxdata.com/kapacitor/v1.5/tick/ https://www.influxdata.com/blog/tick-script-templates/ Historique des alertesLe sous-menu Alerting > Alert history permet d'accéder à l'historique des alertes levées :
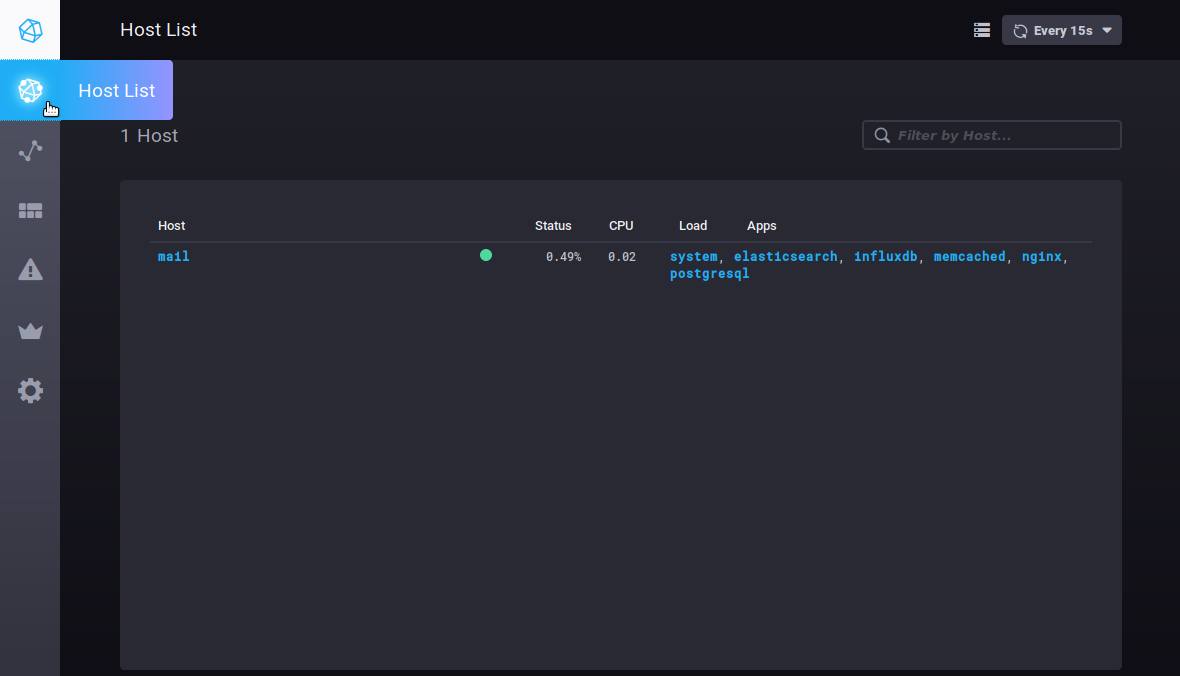
L'historique permet de voir le nom, le niveau, l'heure, l'hôte concerné et la valeur de la donnée lors de la levée de l'alerte. Un clic sur le nom d'hôte mène au tableau de bord de supervision de celui-ci. Autres ongletsLes hôtesL'onglet Host List vous présente la liste des serveurs hôtes surveillés, avec les applications qu'ils comprennent :
Un clic sur un serveur ou sur une application vous mène au tableau de bord spécifique de cet élément. |





| Sv translation | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||||||
Data explorerThe DataExplorer tab is used to browse the database contents, i.e. the metrics collected.
You can write or generate a query by:
The graph with the query results is shown at the bottom of the window. Refresh rates and interval settings are shown and can be edited at the top of the page, as well as in the dashboards:
To look for and analyze a metric:
Useful features/advanced queriesChanging the time interval displayedThis part of the query sets the time interval displayed:
This literally translates as: the data whose time is greater than today minus 7 days, i.e. the data from the past 7 days.
Evolution of a counterCounter data is cumulative and therefore increases regularly. This means that its evolution is more relevant than the data itself. For example, the non_negative_differenceTo watch how this data evolves, you can use the "non_negative_difference" function which returns the non-negative difference between 2 points in the graph. To use the authentication example again, the graph below, with no function applied, shows the mean number of authentications processed by the ysnp component in the last 24 hours, by server and by status:
With an interval difference function, the graph returns the number of authentications for each time interval, you can now see how the amount of authentications processed evolves:
non_negative_derivativeAnother function returns an evolution graph for field values with un additional setting: non_negative_derivative. This function also calculates the difference between 2 points, but in addition, it specifies the unit argument. E.g., the query below shows the mean number of connections (mean("count")) per minute (non_negative_derivative(...,1m)) in the last 24h (where time > now() - 1d) for every hour (group by time(1h)):
distsum metrics comprise 2 types of information:
As a result it may be a pair such as:
Take the This data can be used to calculate an average message size and see whether it evolves abnormally or suddenly. E.g. you may observe a regular increase in average message size over time, which may be down to better connections, servers or user habits etc. but if over a few days average message size suddenly doubles (or more), there's something wrong and you need to find out what: was a corporate signature added? Does it contain an image whose size hasn't been reduced, which increases the size of messages and as a result server load. Useful linksTo find out more about InfluxQL queries, please refer to the documentation: https://docs.influxdata.com/influxdb/v1.6/query_language/ In particular, about fonctions: https://docs.influxdata.com/influxdb/v1.6/query_language/functions/ And grouping by time: https://docs.influxdata.com/influxdb/v1.6/query_language/data_exploration/#advanced-group-by-time-syntax Doing more with graphsThe DataExplorer graphical tool has limited options. For example, you can't create a stacked chart to view the sum of two line graphs. To do this, you need to use the Dashboard's graphs (see next section): DashboardsThe Dashboards tab is used to access to a series of pages where you can group data as desired. By default, 3 tableaux are preconfigured and shown as examples:
You can add as many dashboards as you like, that way you can have customized views of the data you're interested in by grouping it by type, relevance, module, etc.
To create a new dashboard, go to the Dashboard homepage and click "Create dashboard":
The dashboard is created immediately, and an empty view of it opens:
Click "Name this dashboard" to edit the box and enter a name for the dashboard:
To add a graph in the existing area, click The query editor opens. You can create a query either by typing a command or using the database browser. A view of the graph is shown in real time:
This editor is similar to the DataExplorer's. Please refer to the previous section for metrics search and query building. The "Visualization" button is used to choose a graphic type and customize it:
Once your graphic has been created, click "Save" in the top right corner of the editor. The graph is saved and added to the area:
Click
In the top right corner of each cell, three buttons are used to:
Clicking the icon opens a menu of possible actions.
AlertsThe Alerting tab is used to manage alerts as well as alert history.
Alerts can be shown as scripts or as alert rules. By default, there are no alert rules on installation, there are however, a number of pre-set scripts which you can modify. You can also add as many scripts as you like.
Alert rules
Fill in (or edit) the form:
ScriptsScripts are used for advanced alert management. Each alert created as a rule also exists as a script and can be edited using that method.
For more information on writing scripts, please refer to the product's documentation: https://docs.influxdata.com/kapacitor/v1.5/tick/ https://www.influxdata.com/blog/tick-script-templates/ Alert historyThe Alerting > Alert history sub-menu is used to access the history of alerts triggered:
The history shows the name, level, host and value of the data when the alert was triggered. Click the host's name to open its dashboard. Other tabsHostsThe Host List tab shows the list of monitored host servers, with the apps they include:
Clicking a server or an app opens its specific dashboard. |
Vue d'ensemble
Gestion des contenus
Apps